产品简介
功能概述
OpenSearch 是一种托管服务,支持在 AppCenter 管理并升级,为用户提供实时日志处理、全文搜索和数据分析等基础能力。OpenSearch 服务提供与开源版本 Elasticsearch OSS 7.10 的广泛兼容性。
-
OpenSearch 是一个全面开源搜索和分析引擎,用例包括日志分析、实时应用程序监控、点击流分析等,更多说明请参考原生 OpenSearch。
-
OpenSearch 提供集群管理功能。支持在线管理 OpenSearch 集群节点、监控集群和节点信息,以及管理节点配置参数。
基本概念
集群(Cluster)
一个 OpenSearch 集群由一个或多个节点组成,并提供集群内所有节点资源的联合管理索能力。创建集群时系统随机分配通用唯一标识符(UUID)全局唯一,不可修改。同时一个集群的调用,由 ID 标识。用户可以自定义一个集群的名称,以及为集群绑定标签,方便集群分组管理。
节点(Node)
一个节点是集群中的一个服务器,用来存储数据并参与集群的索引和搜索。节点的调用,由一个 ID 标识。用户可以自定义任意节点的名称,节点名称对于管理工作很重要。一个集群可以创建多个节点。
索引(Index)
索引是一个拥有相似特征的文档的集合,相当于关系型数据库中的一个数据库。例如,您可以拥有一个客户数据的索引,一个商品目录的索引,以及一个订单数据的索引。
一个索引通常使用一个名称来标识,当针对这个索引的文档执行索引、搜索、更新和删除操作的时候,这个名称被用来指向索引。
| OpenSearch | 关系型数据库 |
|---|---|
索引(index) |
数据库(database) |
文档类型(type) |
表(table) |
文档(document) |
一行数据(row) |
字段(field) |
一列数据(column) |
映射(mapping) |
数据库的组织和结构(schema) |
类型(Type)
类型通常是一个索引的一个逻辑分类或分区,允许在一个索引下存储不同类型的文档,相当于关系型数据库中的一张表。例如用户类型、博客类型等。
文档(Document)
文档是可以被索引的基本信息单元,相当于关系型数据库中的一行数据。例如,您可以为一个客户创建一个文档。文档可以用 JSON 格式来表示。在一个索引中,您可以存储任意多的文档,且文档必须被索引。
字段(Field)
字段是组成文档的最小单位,相当于关系型数据库中的一列数据。
映射(Mapping)
映射是用来定义一个文档以及其所包含的字段如何被存储和索引,相当于关系型数据库中的 Schema。例如在 Mapping 中定义字段的名称和类型,以及所使用的分词器。
分片(Shards)
OpenSearch 把一个完整的索引分成多个分片,可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
一个分片可以是主分片或副本分片。
-
主分片
支持处理查询和索引请求。在创建索引时设定,设定后不可更改。索引内任意一个文档都存储在一个主分片中,所以主分片的数量和大小决定着索引能够保存的最大数据量。但是,主分片不是越多越好。因为主分片越多,OpenSearch 性能开销也会越大。
-
副本分片
支持处理查询请求,不支持处理索引请求。可在任何时候添加或删除副本分片。副本分片对搜索性能非常重要,主要体现在以下两个方面:
-
提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
-
提高 OpenSearch 的查询效率,OpenSearch 会自动对搜索请求进行负载均衡。
-
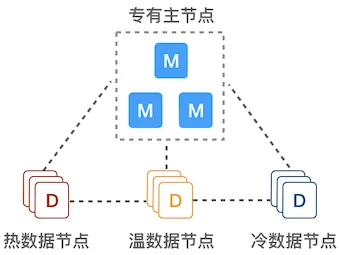
热-温-冷数据架构
热-温-冷数据架构即基于时间创建索引(index)和数据分层存储结构,持续把温/冷数据从热数据节点迁移到相应的数据节点。热-温-冷数据架构常用于在大规模数据分析场景(例如时间数据分析场景),以提高数据的处理效率,以及降低海量数据存储成本。更多说明,请参见"Hot-Warm"Architecture in Elasticsearch 5.x。
-
Master 节点
负责处理集群管理和状态,提高了整体稳定性。Master 节点不保存数据,也不参与搜索和索引操作,不会被长 GC 干扰,负载可以保持在较低水平,能极大提高集群的稳定性。
-
热数据节点
负责处理集群中所有索引,承担最频繁的写入和查询操作。由于索引是 CPU 和 I/O 密集型操作,对计算和存储服务器的性能要求比较高,如超高性能主机及硬盘。
-
温/冷数据节点
负责处理只读索引,会接收少量的查询请求。温/冷数据节点可以配置一般性能的资源,通常配备通用本地磁盘。
应用场景
日志全观测与分析
在复杂业务场景下,海量服务器、物理机、容器、移动设备和 IoT 传感器等设备中,往往存在着结构分散、种类多样、规模庞大的各类指标、日志和数据,对全链路的异常问题定位、业务分析与运维带来了巨大的挑战。用户往往很难从繁杂的日志中获取价值,却要承担其高昂的存储成本。
OpenSearch 服务能够通过 Beats、Logstash 等组件,快速对接各种常见数据源,提供弹性可扩展的集中采集和开箱即用的存储分析能力。借助 OpenSearch Dashboard 可以高效地构建数据可视化运维看板,并在看板中灵活地配置分析。最终帮助您在海量数据中快速定位和发现问题,提高解决问题的效率,从而让日志数据产生价值。
信息检索
每一个生活在移动互联网中的用户,每天都在查询各种各样的信息。例如查询信用卡账单、电子发票、附近的餐厅酒店、媒体咨询、购物订单、交通物流等。为了帮助用户高效获取信息,广大企业需要实现面向海量数据的信息检索服务。
相对于传统关系型数据库,OpenSearch 拥有强大的全文检索能力,并提供了简单易用的 RESTful API 和各种语言客户端。只需要几毫秒的时间,即可在 PB 级结构化和非结构化的数据中找到匹配信息。
OpenSearch 服务具备高可用性和易用性,可实现复杂组合、条件和模糊查询,可轻松应对各类文本、数字、日期、IP 地理数据,乃至图像、音视频数据的高性能读写。从而快速搭建电商商品或订单检索、App 搜索、企业 CRM 系统等检索服务,并可整合到已有业务框架中。
数据智能
随着游戏、教育、零售等各个行业的快速发展,除了底层系统的日志指标数据外,往往还存在着规模庞大的业务数据,例如用户行为、行车轨迹、交易记录等。在数据驱动运营的行业背景下,深入统计分析和挖掘业务数据,为上层业务发现问题与机会并辅助商业决策,才能真正让数据产生价值。
OpenSearch 服务拥有结构化查询能力,并支持复杂过滤和聚合统计功能。
-
通过快速、高效地分析用户行为、属性、标签等各类数据,实现目标人群的精准触达。
-
借助 OpenSearch Dashboard,完成业务数据的统计分类以及大盘的搭建,从而在电子商务、移动应用、广告媒体等多个场景下,高效统计并分析海量数据,深入挖掘业务的数据价值。
产品版本
OpenSearch 目前支持原生 OpenSsearch 和传统 Elasticsearch OSS 版本如下:
| OpenSearch 服务 | 原生 OpenSearch | Elasticsearch OSS |
|---|---|---|
OpenSearch 1.1.0 - v1.0.0 |
1.1.0、1.0.0 |
7.10.2、7.5.1 |
如需启动 OpenSearch 项目,建议选择支持的最新 OpenSearch 版本。若现有区域使用的是较旧的 Elasticsearch 版本,用户可以选择保留或迁移数据。